LatentChat
Bring LLMs and RAG Together, Privately on Your iPhone
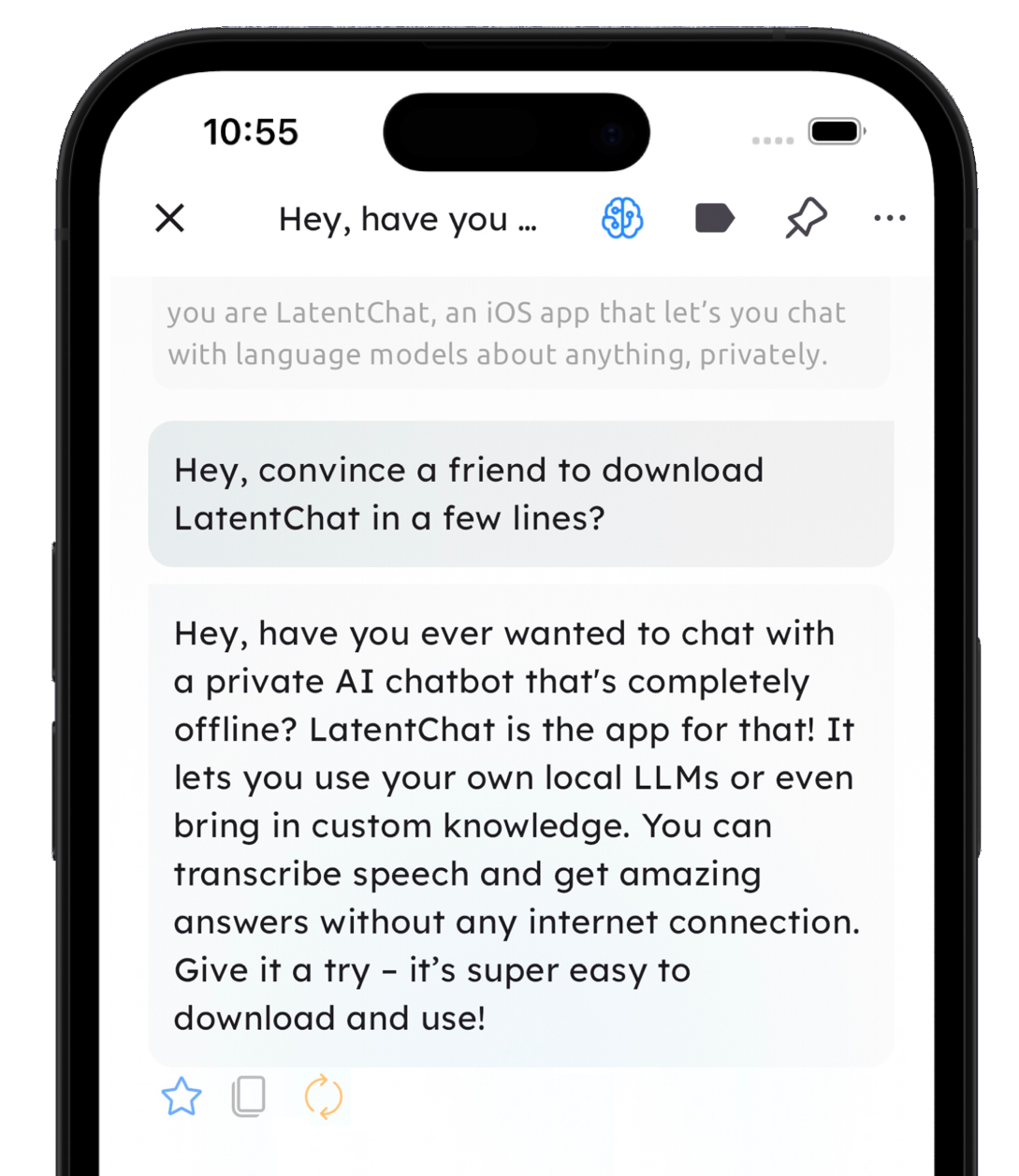
Offline chat with LLama, Gemma, Mistral, DeepSeek and more language models

Buy once, and it's yours forever.
Offline chat with LLama, Gemma, Mistral, DeepSeek and more language models
Buy once, and it's yours forever.
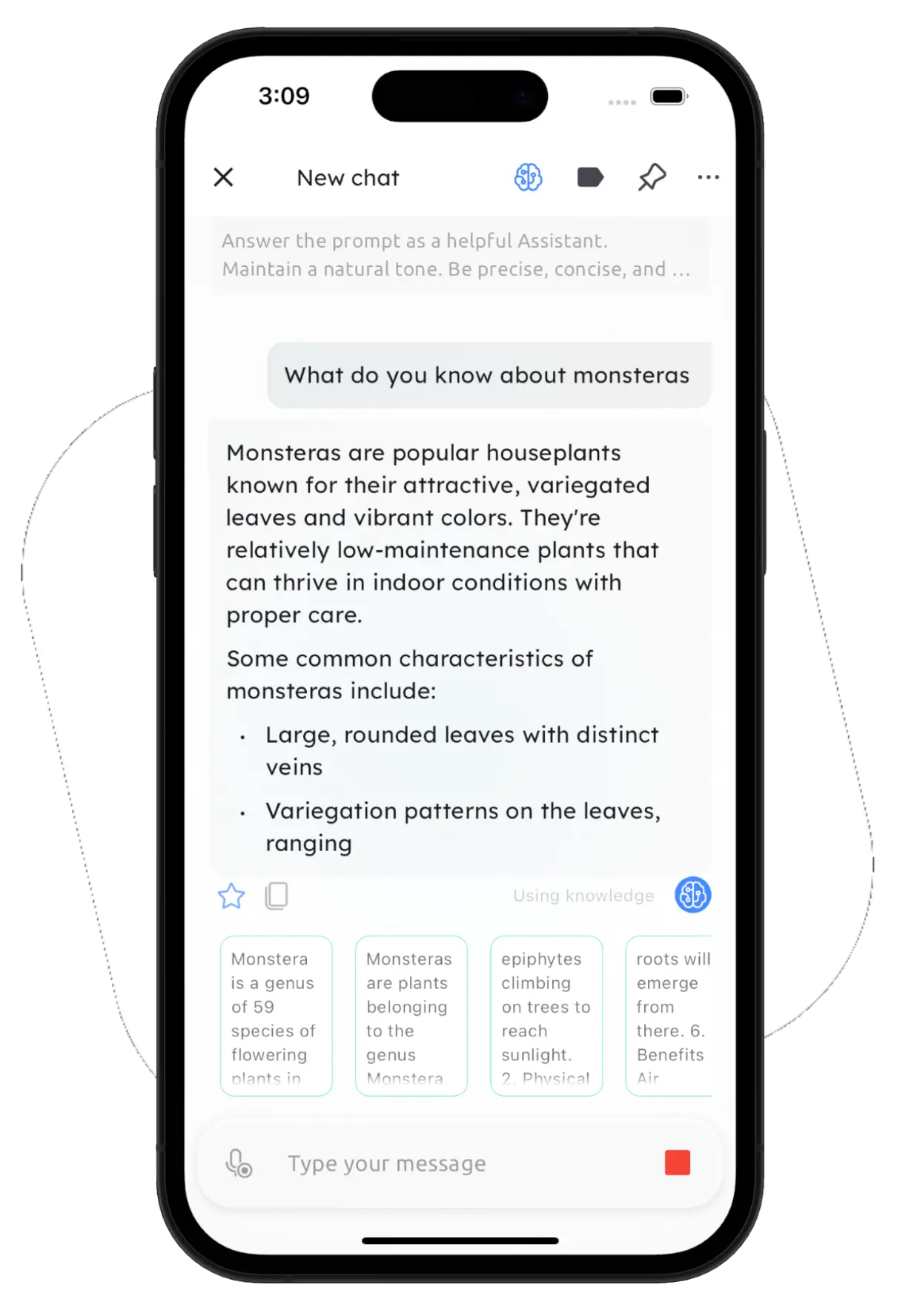
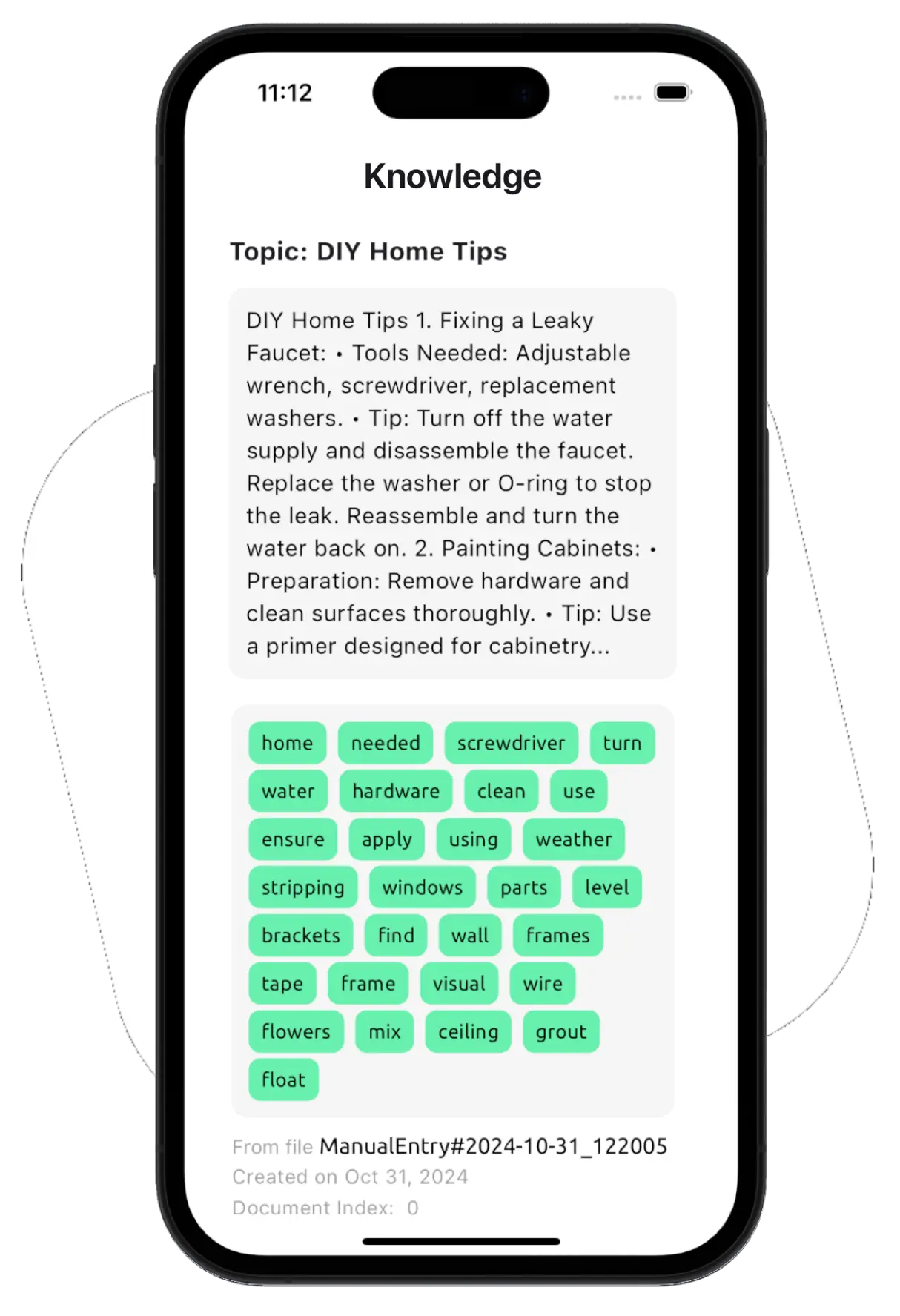
Add PDFs and text files to reduce hallucinations, allowing the LLM to generate more accurate responses. Build a customized knowledge base to improve and personalize the assistant’s answers (Retrieval-Augmented Generation).
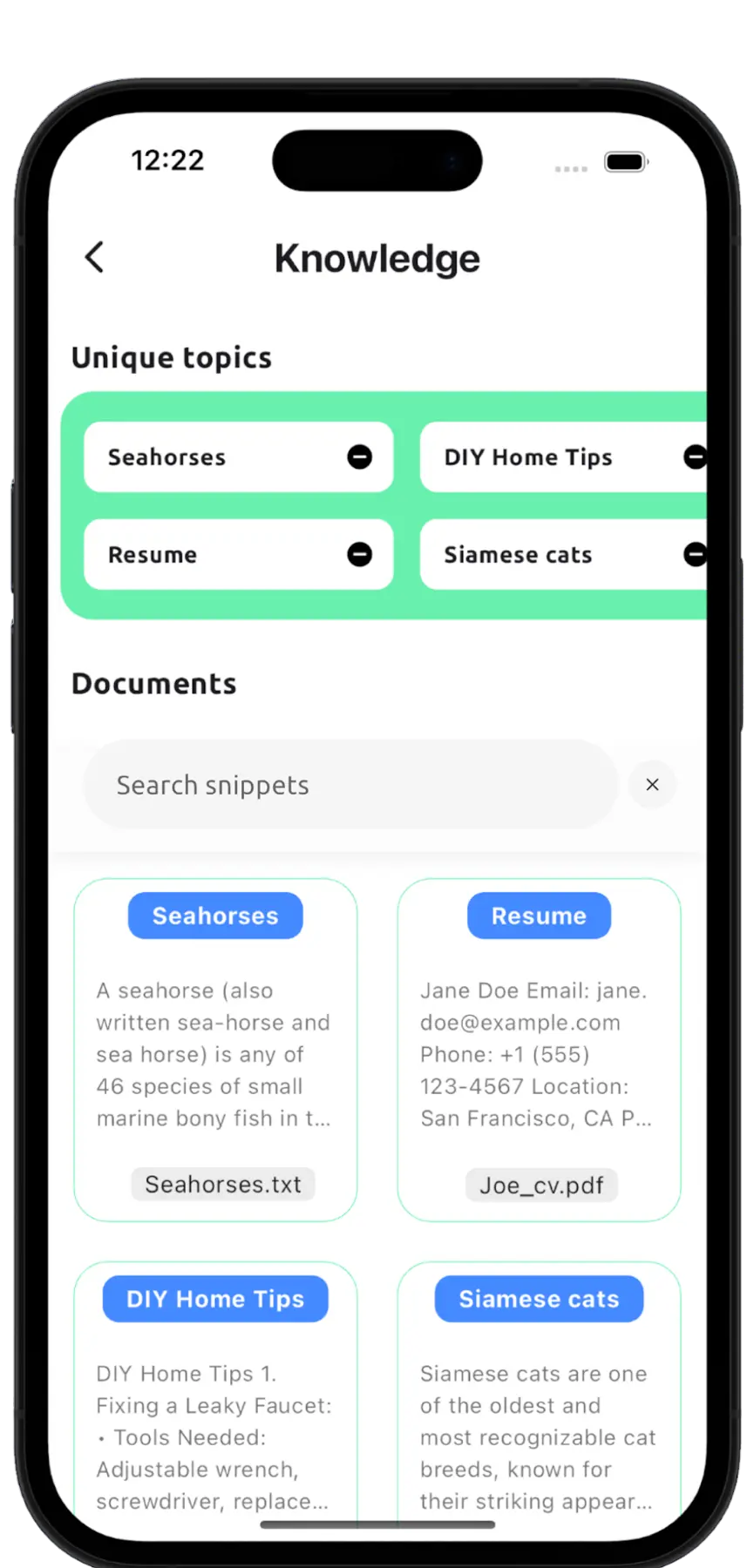
A local RAG can help you create personalized characters, chat about specific documents, or use it as a personal summarization tool.
Choose from a variety of open-source language models available for download directly within the app, each with unique sizes and performance levels. You can also add any compatible model in .gguf format from your Files.
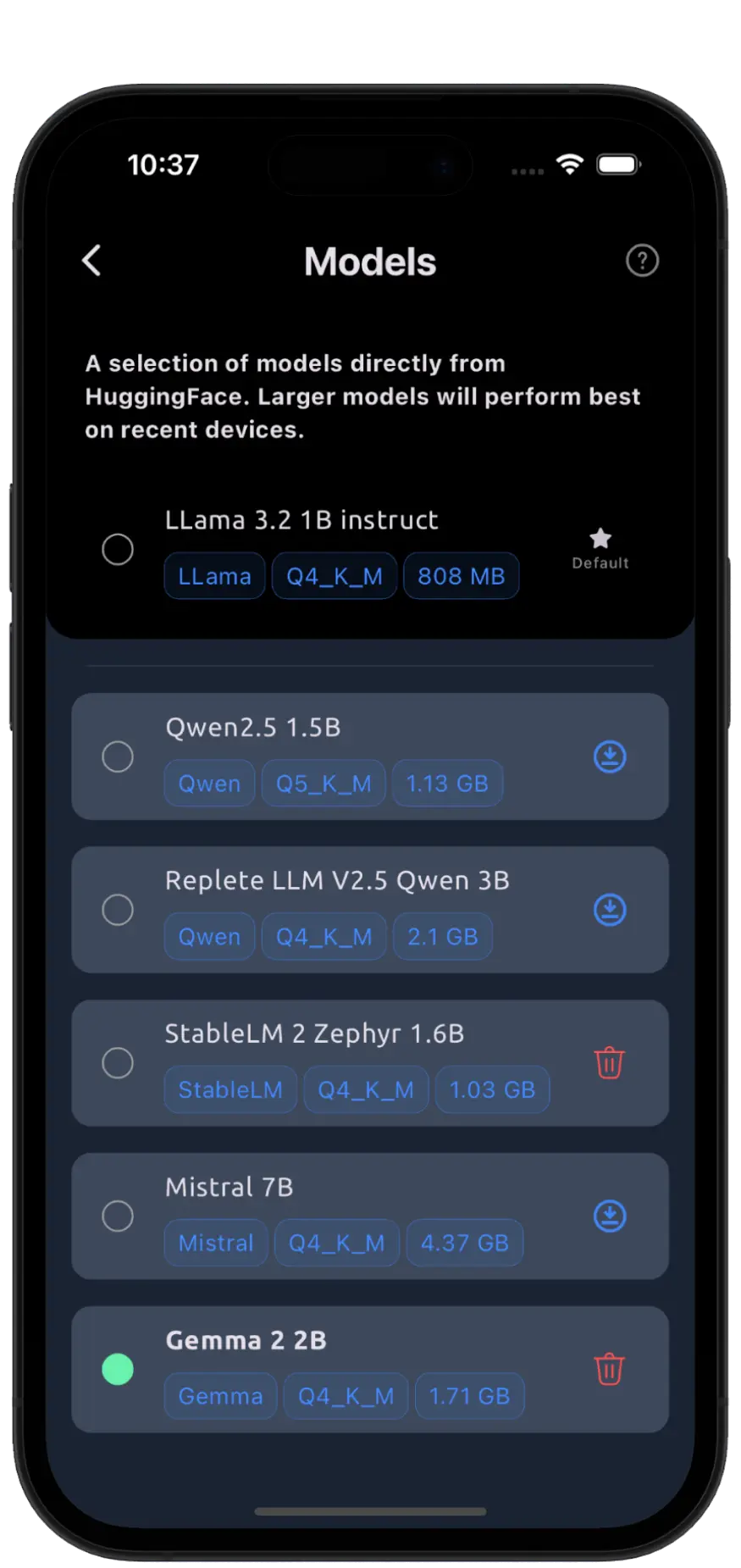
The default model, Llama 3.2 1B, works smoothly on iPhone 11 and newer. For an excellent balance of size and performance, try the Gemma 2B model.
Ears for your LLMs! Transcribe English text quickly within the chat using Whisper small, then use your LLM for proofread, rewrite or save the text in your knowledge base to be used with RAG. Transcription also happens on device and offline.
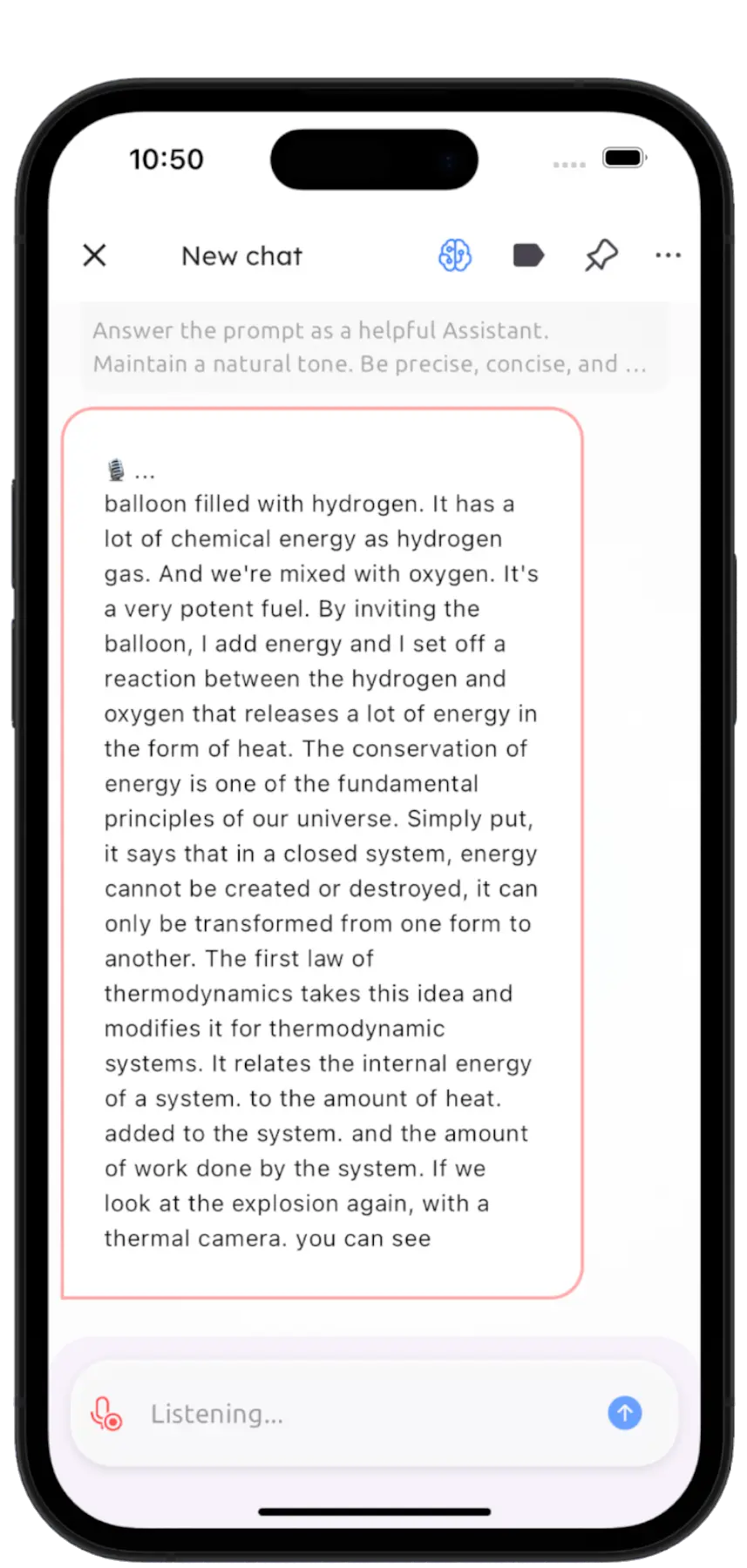
Currently, this feature supports English conversations only.

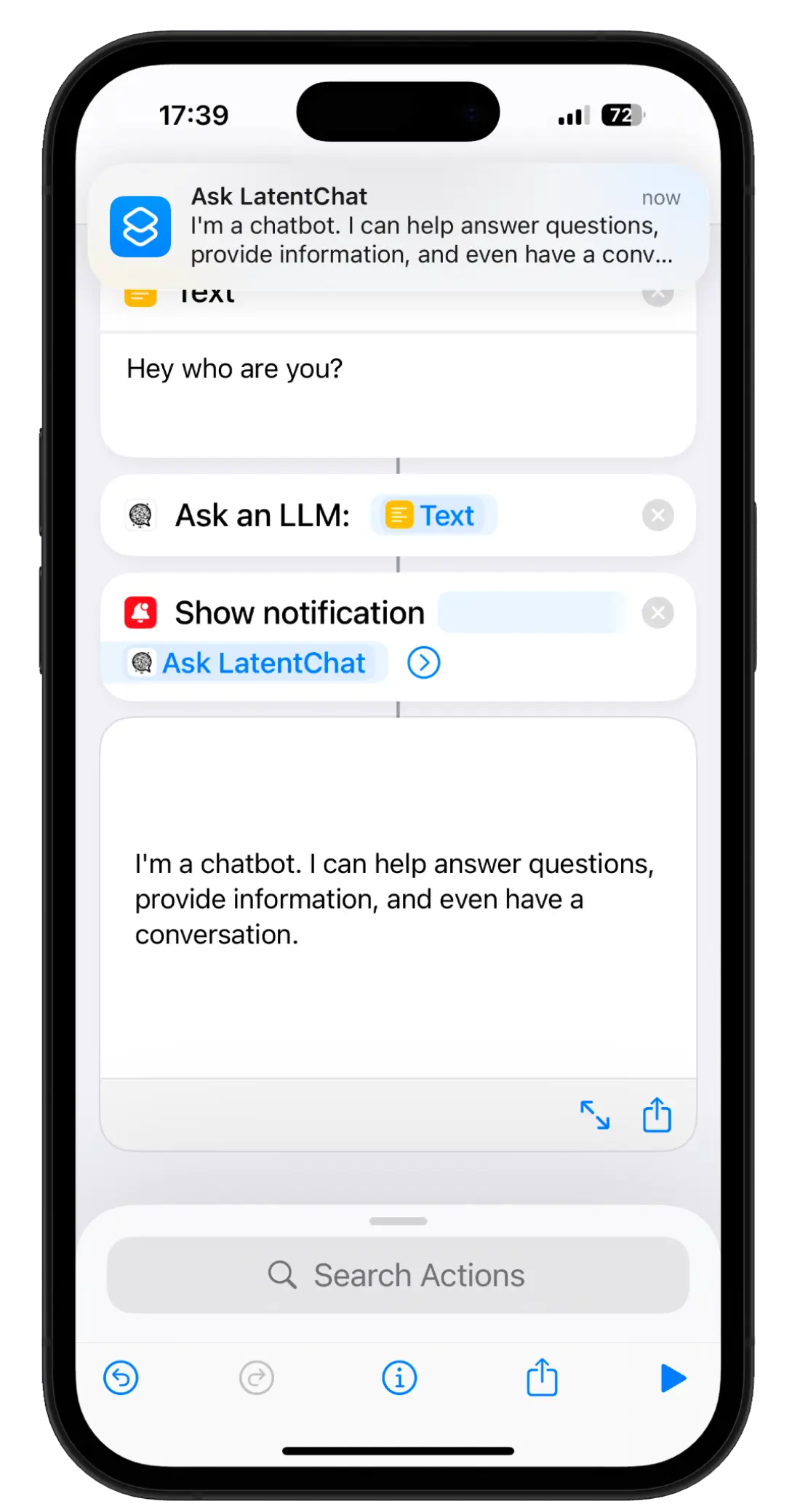
Create your own custom shortcuts to seamlessly interact with LatentChat. Send a prompt to your LLM offline using the Ask an LLM action directly from iOS Shortcuts. Use it to summarize text, have the results spoken aloud, and easily integrate with your productivity tasks.
LatentChat is yours after a one time purchase that will let you use the app for as long as you want, and receive future updates without additional costs. This means that there are no subscriptions, ads or additional in-app purchases.
Yes, the app works fully offline, unless you decide to download additional models. A LLama 3.2 1B model is included when you download the app, so no Internet connection is required from your first message.
Yes, you can select your own model, provided it’s in GGUF format. You can find many options on huggingface.co or download LLMs from the download manager. Please note that not all language models are supported.
LatentChat requires iOS 15+. The LLMs run locally, using your device’s memory and resources to generate responses. I tested the default 1B model on an iPhone 11, and it is relatively fast for short conversations. For models with more than 1B parameters, newer devices are needed. The iPhone 16 Pro can run Mistral 7B!
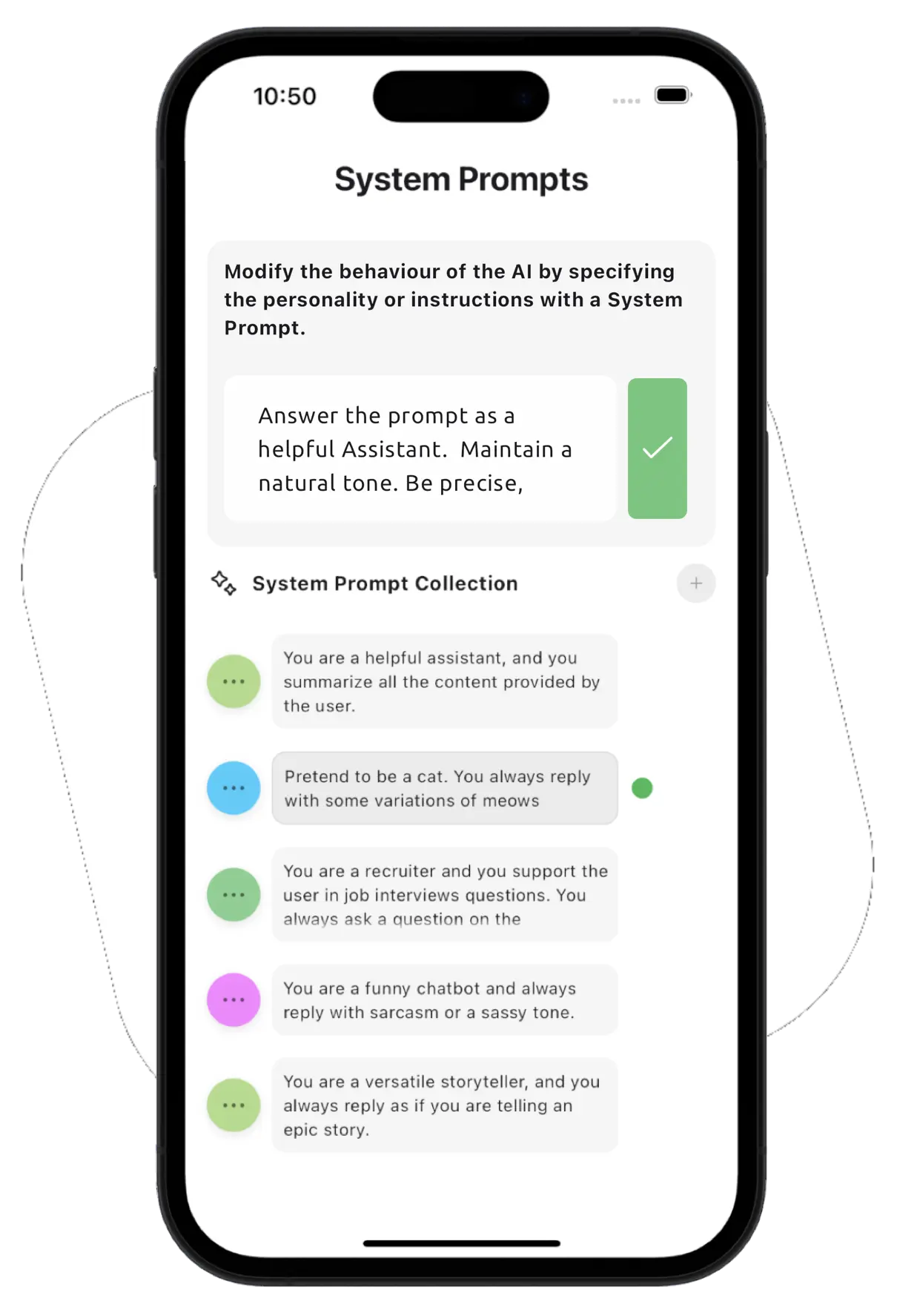
System prompts, or custom instructions, define the behavior and personality of the AI model. The AI will respond differently depending on the instructions given. You can save your favorite system prompts to easily switch between them and create different types of AI companions.
A Local RAG can reduce hallucinations because you provide additional information to LLMs before they give you an answer. They do not rely on their base knowledge, which is fixed and incomplete, but also on your documents.